L’utilizzo della kernel regression prevede la scelta della funzione kernel che andrà a determinare i pesi applicati all’ i-esimo punto di learning (yi) per stimare il j-esimo punto di testing (yj):
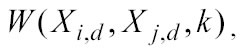 (eq. 2.2.1)
(eq. 2.2.1)
dove Xi,d è l’i-esimo valore di LRN del d-esimo candidate predictors; Xj,d è il j-esimo valore di TST della d-esima dimensione; k è il parametro di smussamento del quale si dirà più avanti. Ci sono tanti tipi di funzioni kernel, molti sono descritti da W.Hardle nel suo libro (vedi bibliografia) e nel help del pacchetto statistico XploRe da lui ideato, tuttavia in questo lavoro viene considerata solamente una funzione esponenziale (vedi Appendice e-mail):
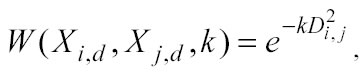
la cui forma cambia al variare del parametro k chiamato smoothing parameter e 2,
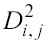
il valore della distanza al quadrato tra i punti delle variabili indipendenti del learning set e quelli del test set. Il parametro k può variare tra 0 e 1: se è pari a 0 tutti i punti sono ugualmente pesati, al suo crescere, invece, ai punti più vicini viene assegnato un peso maggiore rispetto a quelli più distanti.
Kernel Regression: Applicazione alla Previsione del Fib30 Per mostrare come la funzione kernel agisce al variare di k e di 2,
illustra di seguito il grafico che ha in ascissa la distanza al quadrato, e in ordinata il valore assunto da )
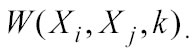
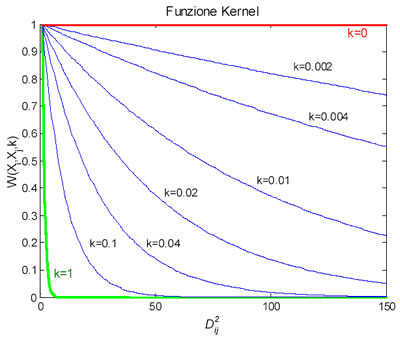
Si deduce chiaramente che più la distanza tra i punti di LRN e ciascun punto di TST è elevata, meno agisce il kernel e la ponderazione decresce esponenzialmente. Inoltre, più k è elevato più il kernel riduce l’effetto del peso sui punti distanti. Si noti che il compito del kernel non è quella di aumentare l’importanza dei punti più vicini, ma di diminuire l’influenza dei punti più lontani relativamente al parametro k.
Successivo: 2.3 La Bandwidth
Sommario: Index